前端框架
web安全
分治法
腾讯云
社区论坛
应届生就业
毛球修剪器方案
区别
虚拟主机
滤波
字节打印流
医疗
Junit使用的基本流程
gitee
vuex
TF-A
动画
.Net6
测试员
python自动化
推导
2024/4/11 20:38:33
【机器学习】最大熵模型推导
1 基本思想
先说说熵的定义,假设我们有随机变量 x,其概率分布为 p(x) ,则其熵为: H(P(x))−∑xP(x)logP(x)条件熵: H(P(y|x))−∑xP(x)∑yP(y|x)logP(y|x)可以证明,在概率相等的时候,熵可以达到最大值。也…

跳跃表的推导和数学证明
skip list引子地铁的例子L1的理想数值让跳跃表更快重新设计地铁线引子
能够完成动态数据的增删改查最简便的数据结构是什么?
是链表。 链表查询的时间复杂度是O(n)。如何修改最简单的链表,能够让它查得快一点呢? 我们可以多增加一些连接&am…

卡尔曼滤波的理解以及参数调整
一、前言
卡尔曼滤波器是一种最优线性状态估计方法(等价于“在最小均方误差准则下的最佳线性滤波器”),所谓状态估计就是通过数学方法寻求与观测数据最佳拟合的状态向量。
在移动机器人导航方面,卡尔曼滤波是最常用的状态估计方…
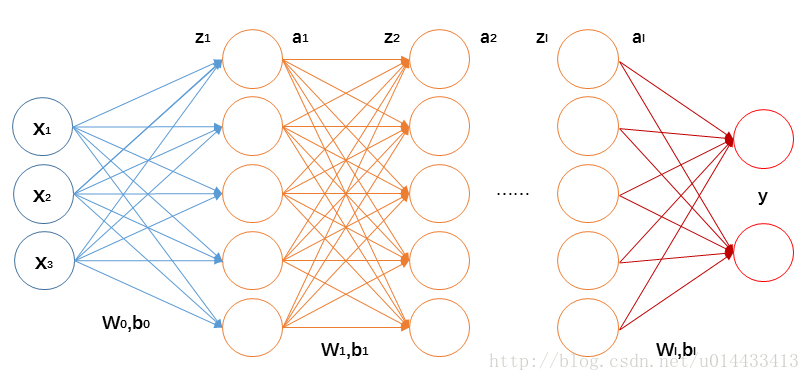
【机器学习】神经网络及BP推导
参考 https://www.zybuluo.com/Feiteng/note/20154
1 前向传播
这里的推导都用矩阵和向量的形式,计算单个变量写起来太麻烦。矩阵、向量求导可参见上面参考的博客,个人觉得解释得很直接很好。
前向传播每一层的计算如下: z(l1)W(l,l1)a(l…


剑指 offer acwing 25 剪绳子 (数学)
题面 题解 这是一道经典的数学结论问题,先说结论,就是我们剪的长度只有2和3两种,而且2最多为2个,当绳子的长度模3余1时,绳子长度为2个2,其余都是3;模3余2时,有一段是2,其…
轻松理解Lambda表达式(推导过程)
文章目录一、简介二、具体使用(推导过程)1、外部类调用2、内部类调用3、Lambda表达式4、开启新的线程(最常使用)三、完整代码一、简介 Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。 …
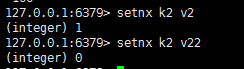
redis分布式锁的层层推导
redisson项目依赖和配置场景与问题使用setnx做锁业务出现异常宕机抽取方法可重入锁自旋续命项目依赖和配置
pom.xml
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>…

【机器学习】支持向量机SVM原理及推导
参考:http://blog.csdn.net/ajianyingxiaoqinghan/article/details/72897399 部分图片来自于上面博客。
0 由来 在二分类问题中,我们可以计算数据代入模型后得到的结果,如果这个结果有明显的区别,这就说明模型可以把数据分开。那…
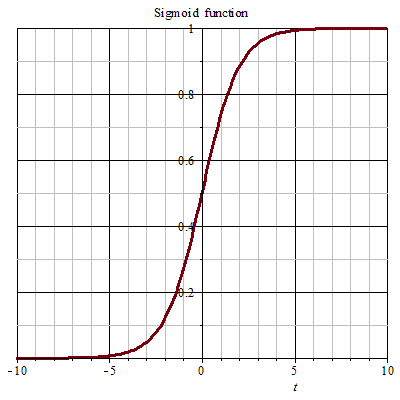
【机器学习】逻辑回归(Linear Regression)模型推导
LR中文翻译作逻辑斯蒂回归,用于二分类。为什么回归和分类搅在一起了呢。因为可以这样想:线性回归 yθTx得到的结果是一个实数。如果我们将这个结果“压缩”到 [0,1] 之间,那么就可以表示概率接近1的程度,进而可以用来二分类。 最简…

【机器学习】Softmax推导
LR可以看成是Softmax的特例。 LR主要是用于二分类,如果面临的是多分类问题,可以用Softmax。Softmax通常也是深度学习图像识别网络的最后一层。 在LR中,参数 θ是一个向量,而在Softmax中,参数可以看成是一个矩阵。也就是…
【机器学习】EM算法推导
1 为什么要用EM算法
有时,我们用极大似然的时候,公式中可能会有隐变量: L(θ)∏i1mp(yi;θ)∏i1m[∑zp(yi,z;θ)]∏i1m[∑zp(z;θ)p(yi|z;θ)]也就是 y 取什么值是由隐含的变量 z 决定的。举个栗子:有三个硬币,ABC&am…